Cum să te descurci cu PSOD - Ecranul violet al morții

This article is available in the following languages:










Cuprins
Ce este PSOD?
De ce se întâmplă acest lucru?
Care este impactul?
Ce trebuie să faci când se întâmplă?
Cum să o prevenim?
TL;DR
Aspectul cel mai problematic al unui PSOD este că vă face să vă pierdeți încrederea în infrastructura dumneavoastră și anxietatea pe care o creează. Până când nu rezolvați cauza principală, gândul că acest lucru se poate întâmpla din nou sau pe un alt server vă poate ține treaz noaptea.
Utilizați Runecast Analyzer (Versiune de încercare gratuită) pentru a verifica dacă vreuna dintre gazdele dvs. este afectată de condițiile care pot provoca ecranul violet al morții VMware.
Ce este PSOD?
PSOD înseamnă Purple Screen of Diagnostics (Ecranul mov de diagnosticare), denumit adesea Purple Screen of Death (derivat din mai cunoscutul Blue Screen of Death (Ecranul albastru al morții), întâlnit uneori în Microsoft Windows).
Este un ecran de diagnosticare afișat de VMware ESXi atunci când nucleul detectează o eroare fatală din care fie nu poate recupera în siguranță, fie nu poate continua să ruleze fără a avea un risc mult mai mare de pierdere majoră de date.
Aceasta arată starea memoriei în momentul blocării și, de asemenea, detalii suplimentare care sunt importante pentru a identifica cauza blocării: Versiunea și construcția ESXi, tipul de excepție, registrul de vidare, backtrace, timpul de funcționare a serverului, mesajele de eroare și informații despre core dump (un fișier generat după eroare, care conține informații suplimentare de diagnosticare).
Acest ecran este vizibil pe consola serverului. Pentru a-l vedea, va trebui fie să vă aflați în centrul de date și să conectați un monitor, fie să folosiți de la distanță gestionarea în afara benzii a serverului (iLO, iDRAC, IMM... în funcție de furnizor).
ȘTIAȚI CĂ?
Ecranul este menționat ca fiind violet sau roz, dar de fapt culoarea este magenta închis (RGB:171,0,171 | CMYK:0.00, 1.00, 0.00, 0.33).
De ce se întâmplă PSOD?
PSOD este o panică a nucleului. Chiar dacă știm cu toții că ESXi nu se bazează pe UNIX, implementarea panicii se încadrează în definiția UNIX. Kernelul ESXi (vmkernel) declanșează această măsură de siguranță ca răspuns la un eveniment/eroare irecuperabil și care ar însemna că continuarea funcționării ar reprezenta un risc ridicat pentru servicii și VM-uri. Pentru a simplifica: atunci când gazdele ESXi simt că au fost corupte, acestea comit "seppuku" și, în timp ce își varsă sângele purpuriu, scriu o scrisoare de sinucidere în care detaliază motivul pentru care au făcut-o!
Cele mai frecvente cauze ale unei PSOD sunt:
1. Defecțiuni hardware, majoritatea legate de RAM sau CPU. În mod normal, acestea generează o eroare "MCE" sau "NMI".
- "MCE" - Machine Check Exception (excepție de verificare a mașinii), care este un mecanism din cadrul procesorului care detectează și raportează problemele hardware. În codurile afișate pe ecranul violet există detalii importante pentru identificarea cauzei principale a problemei.
- "NMI" - întrerupere nemăsurabilă, care este o întrerupere hardware care nu poate fi ignorată de procesor. Deoarece NMI este un mesaj foarte important despre o defecțiune HW, răspunsul implicit începând cu ESXi 5.0 și ulterior este declanșarea unui PSOD. Versiunile anterioare doar înregistrau eroarea și continuau. La fel ca în cazul MCE-urilor, ecranul violet cauzat de NMI va furniza coduri importante care sunt cruciale pentru depanare.
2. Erori de software
- interacțiuni necorespunzătoare între componentele SW ESXi (ex: KB2105711)
- condiții de rasă (ex: KB2136430)
- resurse epuizate: memorie, heap, buffer (ex: KB2034111, KB2150280)
- buclă infinită + depășire de stivă (ex: KB2105522)
- parametrii de configurare necorespunzători sau neacceptați (ex: KB2012125, KB2127997)
3. Drivere care se comportă greșit; erori în drivere care încearcă să acceseze un index incorect sau o metodă inexistentă (ex: KB2148123)
ȘTIAȚI CĂ?
Puteți chiar să declanșați manual un PSOD în scopuri de testare sau dacă sunteți pur și simplu curios să vedeți cum se întâmplă. Conectați-vă la gazda ESXi prin DCUI sau SSH cu un cont privilegiat și rulați:
vsish -e set /reliability/crashMe/Panic
Evident, se recomandă un sistem de testare, în mod ideal un ESXi virtual imbricate, astfel încât să puteți observa cu ușurință consola. De asemenea, asigurați-vă că ați terminat de citit acest articol pentru a înțelege implicațiile acestei acțiuni și efectul asupra sistemului de testare.
Care este impactul PSOD?
Atunci când apare panica și gazda se prăbușește, toate serviciile care rulează pe ea, împreună cu toate mașinile virtuale găzduite, sunt oprite. Mașinile virtuale nu sunt închise în mod grațios, ci mai degrabă sunt oprite brusc. În cazul în care gazda face parte dintr-un cluster și ați configurat HA, aceste VM vor fi pornite pe celelalte gazde din cluster. Pe lângă întreruperea și indisponibilitatea mașinilor virtuale în perioada în care acestea sunt oprite, unele aplicații critice, cum ar fi serverele de baze de date, cozile de mesaje sau lucrările de backup pot fi afectate de oprirea "murdară".
În plus, toate celelalte servicii furnizate de gazdă vor fi întrerupte, astfel încât, dacă gazda dvs. este membră a unui cluster VSAN, un PSOD va afecta și vSAN.
Pentru mine, cel mai problematic aspect al unui PSOD este că te face să-ți pierzi încrederea în infrastructura ta și în anxietatea pe care o creează, cel puțin până când ajungi la capăt. Bine, poți recupera prin repornire și este posibil să ai HA sau chiar FT, astfel încât impactul să nu fie devastator... dar până nu rezolvi cauza principală, gândul că acest lucru se poate întâmpla din nou sau pe un alt server te poate ține treaz noaptea.
Ce trebuie să faceți atunci când se întâmplă PSOD?
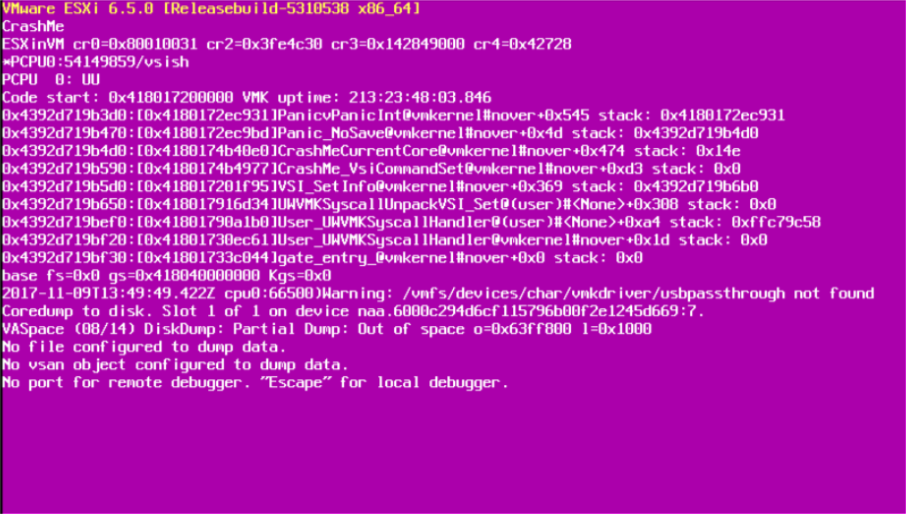
1. Analizați mesajul de pe ecranul violet
Unul dintre cele mai importante lucruri pe care trebuie să le faceți atunci când aveți un PSOD este să faceți o captură de ecran. Dacă vă conectați de la distanță (IMM, iLO, iDRAC...) la consolă, va fi ușor să faceți o captură de ecran, dar dacă trebuie să mergeți la centrul de date, s-ar putea să fiți nevoit să scoateți literalmente telefonul și să faceți o fotografie a ecranului. În acel ecran există o mulțime de informații utile despre cauza accidentului.
2. Contactați serviciul de asistență VMware
Înainte de a începe investigațiile și depanarea, este recomandabil să contactați serviciul de asistență VMware, dacă aveți un contract de asistență. În paralel cu investigația dumneavoastră, aceștia vă vor putea ajuta la realizarea analizei cauzelor de bază (RCA).
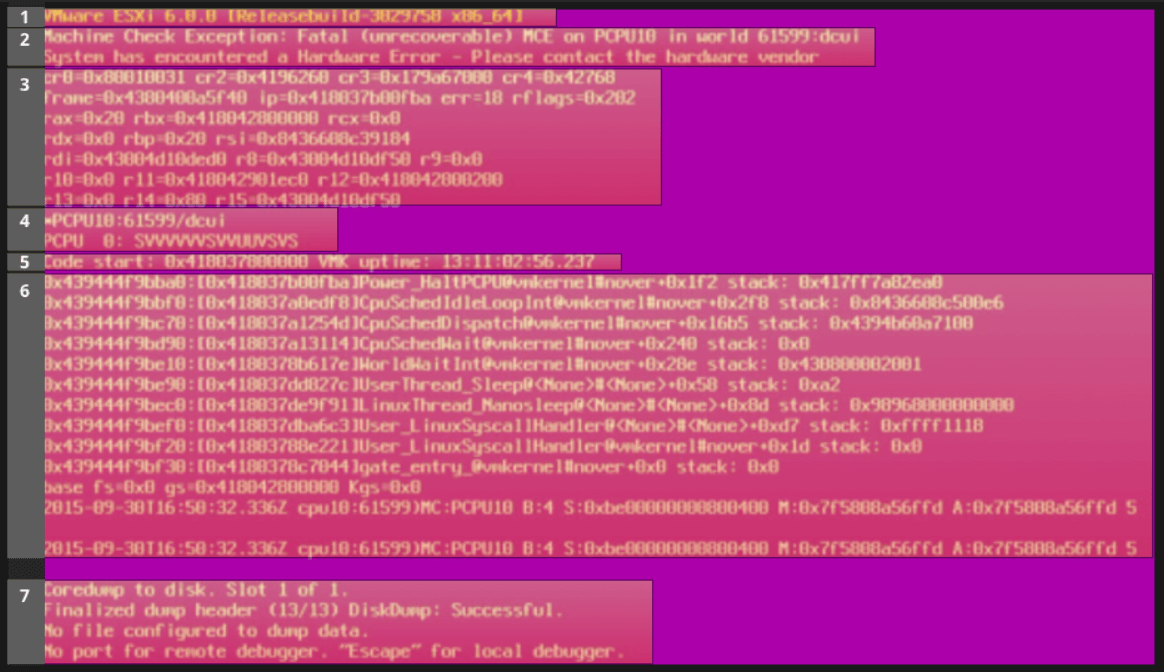
3. Reporniți gazda ESXi afectată
Pentru a recupera serverul, va trebui să îl reporniți. De asemenea, v-aș sfătui să îl păstrați în modul de întreținere până când efectuați un RCA complet, identificați cauza și o remediați. Dacă nu vă puteți permite să îl mențineți în modul de întreținere, cel puțin reglați bine regulile DRS astfel încât doar VM-urile neimportante să ruleze pe el, astfel încât, dacă un alt PSOD lovește, impactul va fi minim.
4. Obțineți descărcarea nucleului
După ce serverul pornește, ar trebui să colectați coredump-ul. Coredump, numit și vmkernel-zdump, este un fișier care conține jurnale cu informații similare, dar mai detaliate decât cele observate pe ecranul de diagnosticare violet și va fi utilizat în continuare pentru depanare. Chiar dacă cauza blocării poate părea evidentă din mesajul PSOD pe care l-ați analizat la pasul 1, este recomandabil să o confirmați prin consultarea jurnalelor din coredump.
În funcție de configurația dumneavoastră, este posibil să aveți descărcarea nucleului în una dintre aceste forme:
a. Pe partiția scratch
b. Ca un fișier .dump pe unul dintre stocurile de date ale gazdei.
c. Ca fișier .dump pe vCenter - prin serviciul netdump
Coredump-ul devine deosebit de important în cazul în care configurația gazdei trebuie resetată automat după un PSOD, caz în care nu veți putea vedea mesajul pe ecran.
Puteți copia fișierul de descărcare din gazda ESXi folosind SCP și apoi îl puteți deschide folosind un editor de text (cum ar fi Notepad++). Acesta va conține conținutul memoriei în momentul accidentului, iar primele părți ale acestuia conțin mesajele pe care le-ați văzut pe ecranul violet. Întregul fișier poate fi solicitat de către suportul VMware, dar puteți extrage doar jurnalul vmkernel, care este un pic mai... digerabil:
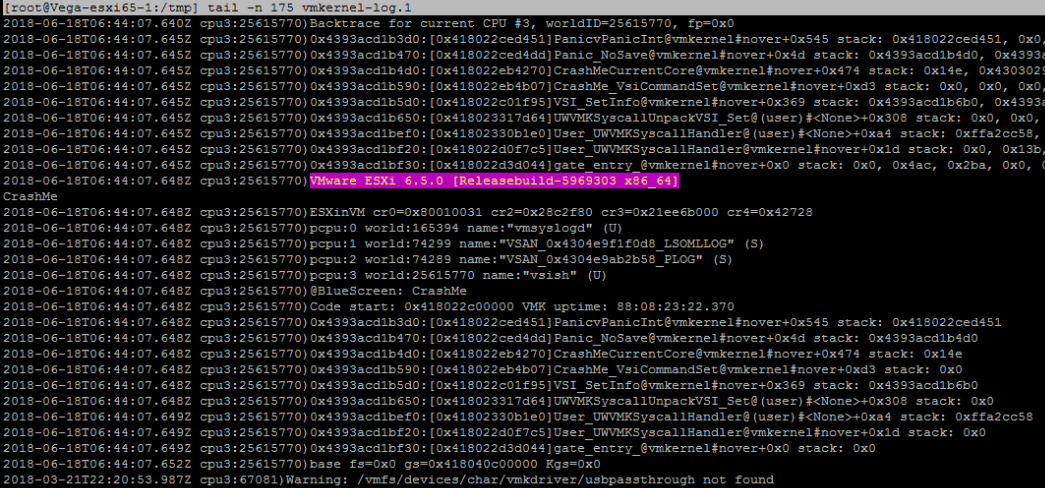
5. Descifrați eroarea
Rezolvarea problemelor și analiza cauzelor care le generează pot face pe cineva să se simtă ca Sherlock Holmes. PSOD-urile se pot transforma uneori într-o poveste inspirată de Arthur Conan Doyle, dar, în majoritatea cazurilor, este un proces destul de simplu, în care va fi greu să ajungi la al cincilea "de ce" din tehnica celor 5 motive.
Cel mai important simptom și cel cu care ar trebui să începeți este mesajul de eroare generat de ecranul violet. Din fericire, numărul de mesaje de eroare care pot fi produse este finit:
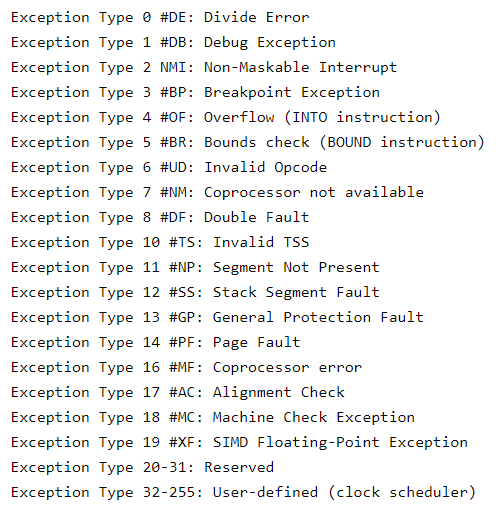
Deoarece panica nucleului este gestionată de CPU, pentru mai multe informații despre aceste excepții, consultați Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 1: Basic Architecture și Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 3A.
Cele mai frecvente cazuri sunt tratate în articole separate din VMware KB și voi păstra aici doar un tabel de referință al acestor erori, deoarece articolele sunt foarte detaliate și bine documentate. Așadar, utilizați acest tabel ca index pentru erorile PSOD:
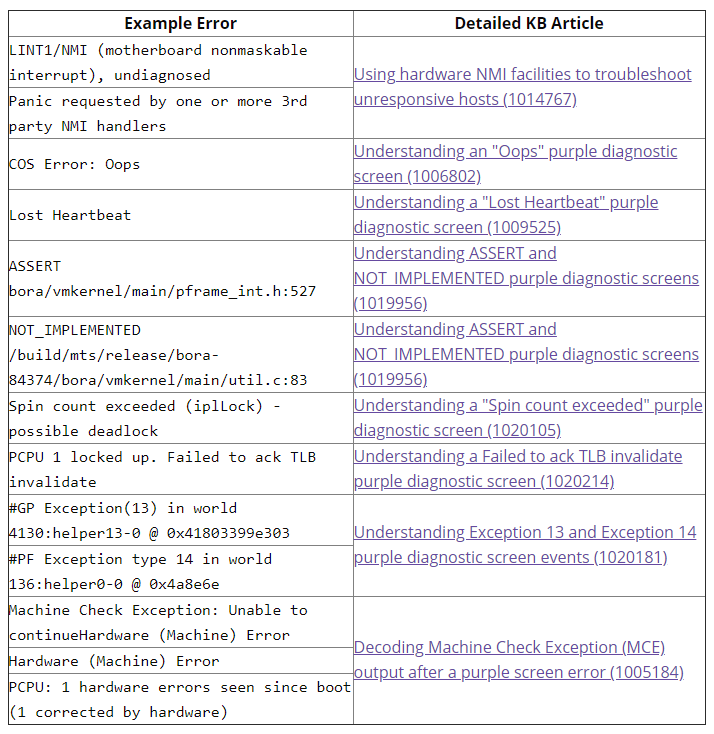
6. Verificați jurnalele
Se poate întâmpla ca cauza să nu fie foarte evidentă dacă vă uitați la mesajul de pe ecranul violet sau la jurnalul de descărcare a nucleului, așa că următorul loc unde trebuie să căutați indicii este în jurnalele gazdei, în special în intervalul de timp care precede PSOD. Chiar și atunci când credeți că ați localizat cauza, este totuși recomandabil să evitați să fiți parcimonios și să o confirmați prin consultarea jurnalelor.
Dacă administrați un mediu de întreprindere, este probabil că aveți la îndemână o soluție specializată de gestionare a jurnalelor (cum ar fi VMware Log Insight sau SolarWinds LEM), astfel încât va fi ușor să răsfoiți aceste jurnale, dar dacă nu aveți o soluție de gestionare a jurnalelor, le puteți exporta cu ușurință.
Cele mai interesante fișiere jurnal de explorat ar fi:

Cum să prevenim PSOD?
Majoritatea PSOD-urilor legate de software sunt rezolvate prin patch-uri, așa că asigurați-vă că sunteți la zi cu cele mai recente versiuni.
Asigurați-vă că serverele dvs. se află pe lista de verificare a compatibilității hardware a VMware, împreună cu toate dispozitivele și adaptoarele. Acest lucru vă va proteja de unele dintre problemele neașteptate legate de hardware, dar va asigura, de asemenea, că serviciul de asistență VMware va putea să vă ofere asistență în cazul unui PSOD.
După cum s-a descris mai sus în secțiunea "De ce se întâmplă", driverele cu comportament necorespunzător sunt, de asemenea, o cauză frecventă a PSOD-urilor, astfel încât este imperativ să verificați în mod regulat site-urile de asistență ale furnizorilor pentru firmware și drivere actualizate și, în special, pentru driverele care cauzează PSOD documentate, pentru a răspunde cât mai curând posibil prin actualizarea acestora.
La Runecast, analizăm în mod regulat întreaga bază de cunoștințe VMware (kb.vmware.com), care cuprinde peste 30.000 de articole. Extragem informații utile din KB pentru a face infrastructurile virtualizate mai rezistente, mai sigure și mai eficiente în mod proactiv. Cunoaștem foarte bine PSOD și suntem capabili să identificăm majoritatea condițiilor prealabile care pot duce la această problemă. Analizând în mod proactiv mediul dumneavoastră, Runecast Analyzer vă va ajuta să vă feriți de aceste probleme, astfel încât să aveți liniștea că majoritatea PSOD-urilor care pândesc mediul dumneavoastră sunt prevenite.
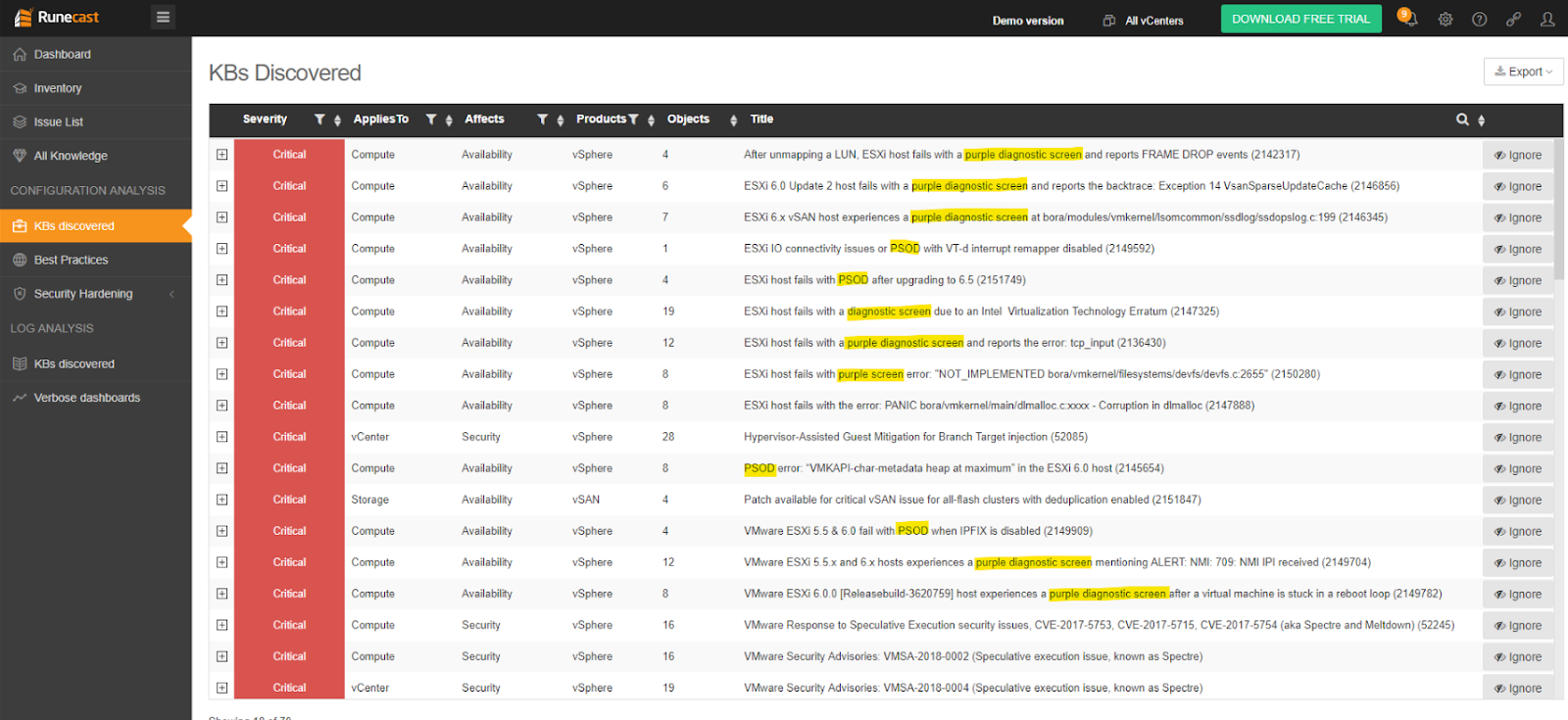
>> Descărcați Runecast Analyzer free trial (în limba engleză)
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Ebook - How to Deal with PSOD (în limba engleză)
Tot ce trebuie să știți despre PSOD (The Purple Screen of Death), într-un ebook realizat de Aylin Sali, CTO al Runecast.