Como Lidar com PSOD – O ecrã roxo da morte

This article is available in the following languages:










Conteúdos
O que é PSOD?
Porque é que isso acontece?
Qual é o impacto?
O que fazer quando isso acontece?
Como evitá-lo?
TL;DR
O aspeto mais problemático de um PSOD é que o faz perder a confiança nas suas infraestruturas e a ansiedade que cria. Até que não resolva a causa raiz, a ideia de que isto pode acontecer novamente ou noutro servidor pode mantê-lo acordado durante a noite.
Utilize o Runecast Analyzer (Teste gratuito) para verificar se algum dos seus servidores é afetado por condições que podem causar o ecrã roxo da morte do VMware.
O que é PSOD?
PSOD significa Ecrã Roxo de Diagnóstico, frequentemente referido como Ecrã Roxo da Morte (derivado do Ecrã Azul da Morte, mais conhecido por vezes encontrado no Microsoft Windows).
É um ecrã de diagnóstico apresentado pelo VMware ESXi quando o core detecta um erro fatal do qual ou não consegue recuperar com segurança, ou não pode continuar a funcionar sem ter um risco muito maior de perda de dados importantes.
Mostra o estado da memória no momento do incidente e também detalhes adicionais que são importantes na resolução de problemas da causa do incidente: ESXi versão e revisão, tipo de exceção, registo dump, backtrace, tempo de funcionamento do servidor, mensagens de erro e informação sobre o dump do core (um ficheiro gerado após o erro, contendo mais informação de diagnóstico).
Este ecrã é visível na consola do servidor. Para o ver, terá de estar no centro de dados e ligar um monitor, ou remotamente utilizando a gestão fora da banda do servidor (iLO, iDRAC, IMM... dependendo do seu fornecedor).
VOCÊ JÁ SABIA?
O ecrã é referido como Roxo ou Rosa , mas na realidade a cor é Magenta Escura (RGB:171,0,171 | CMYK:0.00, 1.00, 0.00, 0.33)
Porque é que o PSOD acontece?
O PSOD é um evento de pânico. Embora todos saibamos que o ESXi não se baseia no UNIX, a implementação do pânico enquadra-se na definição do UNIX. O core do ESXi (vmkernel) desencadeia esta medida de segurança em resposta a um evento/erro que é irrecuperável e que significaria que continuar a funcionar representaria um risco elevado para os serviços e VMs. Dito de forma simples: quando os servidores do ESXi se sentem corrompidos, cometem "seppuku" e, enquanto sangram o seu sangue púrpura, escrevem uma carta de suicídio detalhando porque o fizeram!
As causas mais comuns de um PSOD são:
1. Falhas de hardware, na sua maioria relacionadas com RAM ou CPU. Normalmente deitam fora um erro "MCE" ou "NMI".
- "MCE" - Machine Check Exception, que é um mecanismo dentro da CPU para detetar e reportar problemas de hardware. Existem detalhes importantes para identificar a causa raiz do problema nos códigos apresentados no ecrã roxo.
- "NMI" - interrupção não-mascarável, que é uma interrupção de hardware que não pode ser ignorada pelo processador. Uma vez que a NMI é uma mensagem muito importante sobre uma falha HW, a resposta padrão começando com ESXi 5.0 e posteriores é desencadear um PSOD. As versões anteriores estavam apenas a registar o erro e a continuar. Tal como nos MCEs, o ecrã roxo causado pelo NMI irá fornecer códigos importantes que são cruciais para a resolução de problemas.
2. Bugs de software
- interações impróprias entre componentes ESXi SW (ex: KB2105711)
- condições competitivas (ex: KB2136430)
- falta de recursos: memória, pilha, buffer (ex: KB2034111, KB2150280)
- infinite loop + stack overflow(ex: KB2105522)
- parâmetros de configuração impróprios ou não suportados (ex: KB2012125, KB2127997)
3. Controladores mal-comportados; erros nos controladores que tentam aceder a algum índice incorreto ou método inexistente (ex: KB2148123)
VOCÊ JÁ SABIA?
Pode mesmo causar manualmente um PSOD para fins de teste ou se estiver apenas curioso para o ver acontecer.
Inicie a sessão no anfitrião ESXi via DCUI ou SSH com uma conta privilegiada e funcione:
vsish -e set /reliability/crashMe/Panic
Obviamente recomenda-se um sistema de teste, idealmente um ESXi virtual “nested” para que possa facilmente observar a consola. Certifique-se também de terminar de ler este artigo para compreender as implicações desta acão e o efeito no seu sistema de teste.
Qual é o impacto do PSOD?
Quando o pânico ocorre e o anfitrião cai, termina todos os serviços que nele funcionam juntamente com todas as máquinas virtuais alojadas. As VMs não são desligadas graciosamente, mas sim abruptamente desligadas. Se o servidor fizer parte de um cluster e tiver configurado HA, estas VMs serão iniciadas nos outros servidores do cluster. Para além da interrupção e indisponibilidade das VMs durante o tempo em que estão desligadas, algumas aplicações críticas como servidores de bases de dados, filas de mensagens ou trabalhos de backup podem ser afetados pelo encerramento "sujo".
Além disso, todos os outros serviços prestados pelo servidor serão terminados, portanto, se o seu servidor for membro de um cluster VSAN, um PSOD também terá impacto na vSAN.
Para mim, o aspeto mais problemático de um PSOD é que o faz perder a confiança nas suas infraestruturas e a ansiedade que cria, pelo menos até chegar ao fundo da questão. Ok, pode recuperar reiniciando e pode ter HA ou mesmo FT, pelo que o impacto pode não ser devastador... mas até resolver a causa raiz, a ideia de que isto pode acontecer novamente ou noutro servidor pode mantê-lo acordado durante a noite.
O que fazer quando o PSOD acontece?
1. Analisar a mensagem do ecrã roxo
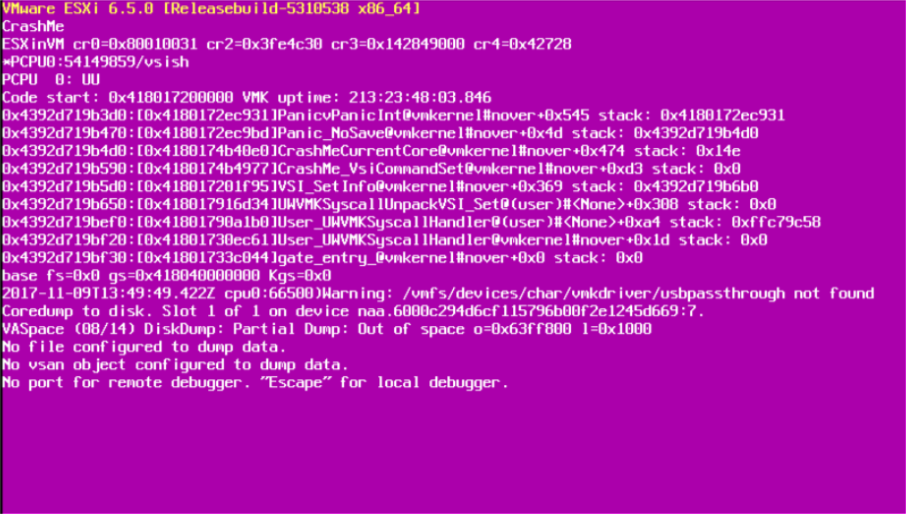
Uma das coisas mais importantes a fazer quando se tem uma PSOD é tirar uma fotografia do ecrã. Se estiver ligado remotamente (IMM, iLO, iDRAC...) à consola, será fácil tirar uma fotografia do ecrã, mas se tiver de ir ao centro de dados, poderá ter de tirar literalmente o telefone e tirar uma fotografia do ecrã. Há muita informação útil sobre a causa da queda nesse ecrã.

2. Contacte o suporte VMware
Antes de iniciar mais investigação e resolução de problemas é aconselhável contactar o suporte VMware, se tiver um contrato de suporte. Em paralelo com a sua investigação, poderão ajudá-lo a fazer a Análise da Causa Raiz (RCA).
3. Reiniciar o servidor ESXi afectado
A fim de recuperar o servidor, terá de o reiniciar. Aconselho também a mantê-lo em modo de manutenção até efetuar a RCA completa, identificar a causa, e corrigi-la. Se não se puder dar ao luxo de o manter em modo de manutenção, pelo menos aperfeiçoe as suas regras DRS para que apenas VMs sem importância funcionem nele, para que se outro PSOD atingir o impacto seja mínimo.
4. Obter o despejo do núcleo
Após a inicialização do servidor, deverá recolher o coredump. O coredump, também chamado vmkernel-zdump é um ficheiro contendo registos com informação semelhante, mas mais detalhada do que a vista no ecrã de diagnóstico roxo e será utilizado na resolução de outros problemas. Mesmo que a causa do acidente possa parecer óbvia a partir da mensagem PSOD que analisou no passo 1, é aconselhável confirmá-la através da observação dos registos do coredump.
Dependendo da sua configuração, poderá ter o dump do core numa destas formas:
a. Na partição scratch
b. Como um ficheiro .dump num dos datastores do servidor
c. Como ficheiro .dump no vCenter - através do serviço netdump
O coredump torna-se especialmente importante se a configuração do servidor for reiniciar automaticamente após um PSOD, caso em que poderá não ver a mensagem no ecrã.
Pode copiar o ficheiro de dump do servidor ESXi usando o SCP e depois abri-lo usando um editor de texto (como o Notepad++). Este terá o conteúdo da memória no momento do acidente e as primeiras partes da mesma contêm as mensagens que viu no ecrã roxo. O ficheiro inteiro pode ser solicitado pelo suporte VMware, mas pode extrair o log vmkernel apenas, que é um pouco mais ... digerível:
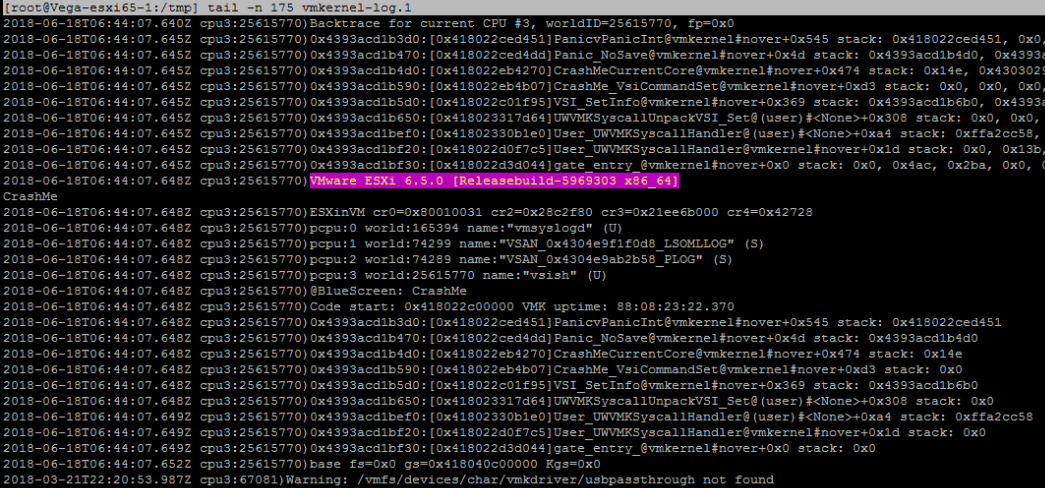
5. Decifrar o erro
A Resolução de Problemas e Análise da Causa Raiz pode fazer-nos sentir como Sherlock Holmes. Os PSODs podem por vezes transformar-se numa história inspirada em Arthur Conan Doyle, mas na maioria dos casos, é um processo bastante simples onde será difícil chegar ao quinto "porquê" da técnica dos 5 Whys.
O sintoma mais importante, e aquele com que se deve começar, é a mensagem de erro gerada pelo ecrã roxo. Felizmente, o número de mensagens de erro que podem ser produzidas é finito:
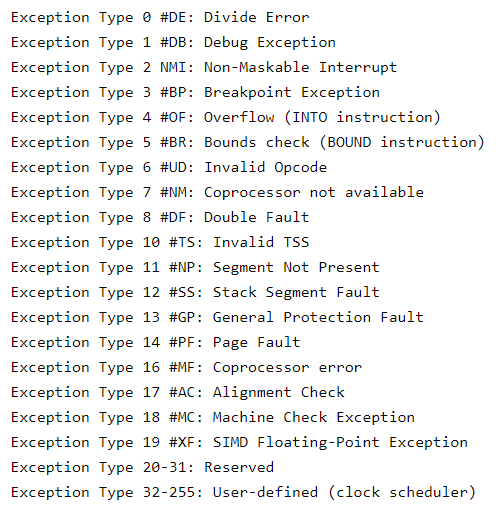
Uma vez que o pânico no core é tratado pelo CPU, para mais informações sobre estas exceções ver Intel 64 e IA-32 Architectures Software Developer's Manual, Volume 1: Basic Architecture e Intel 64 e IA-32 Architectures Software Developer's Manual, Volume 3A.
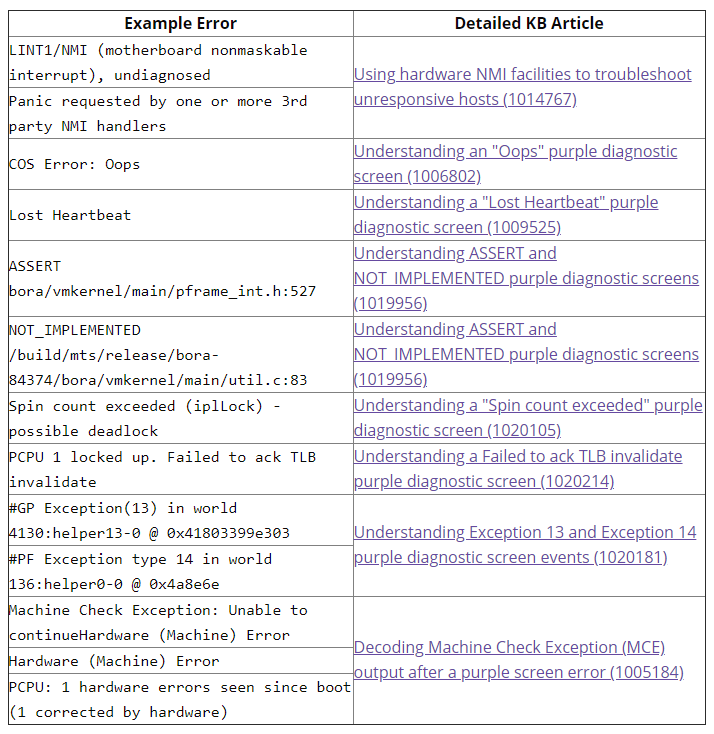
Os casos mais comuns são cobertos em artigos separados do VMware KB e vou apenas manter aqui uma tabela de referência desses erros, uma vez que os artigos são muito detalhados e bem documentados. Portanto, use esta tabela como um índice para os erros PSOD:
6. Verificar registos
Pode acontecer que a causa não seja muito óbvia ao olhar para a mensagem de ecrã roxo ou para o registo central do dump, pelo que o próximo local onde procurar pistas é nos logs do servidor, especialmente no intervalo de tempo que precede o PSOD. Mesmo quando sentir que localizou a causa, é aconselhável evitar ser parcimonioso e confirmá-la através da observação dos logs.
Se estiver a administrar um ambiente empresarial, é provável que tenha em mãos alguma solução especializada de gestão de logs (como VMware Log Insight ou SolarWinds LEM), pelo que será fácil navegar através desses logs, mas se não tiver uma gestão de logs pode facilmente exportá-los.
Os ficheiros de registo mais interessantes a explorar seriam:

Como prevenir o PSOD?
A maioria dos PSODs relacionados com software são resolvidos por pacotes de correcção, por isso certifique-se de que está atualizado com as versões mais recentes.
Certifique-se de que os seus servidores estão na lista de verificação de compatibilidade de hardware da VMware, juntamente com todos os dispositivos e adaptadores. Isto protegerá de alguns dos problemas inesperados relacionados com hardware, mas também assegurará que o suporte VMware será capaz de o apoiar no caso de um PSOD.
Tal como descrito acima em "Porque acontece", os controladores mal comportados são também uma causa frequente de PSODs, pelo que é imperativo verificar regularmente os sítios web de apoio dos fabricantes em busca de firmware e controladores atualizados e especialmente para os PSODs documentados, fazendo com que os contoladores respondam o mais rapidamente possível através da sua atualização.
Na Runecast, analisamos regularmente toda a Base de Conhecimento VMware (kb.vmware.com) que consiste em mais de 30.000 artigos. Estamos a extrair insights acionáveis dos KBs a fim de tornar proactivamente as infraestruturas virtualizadas mais resilientes, seguras e eficientes. Estamos muito familiarizados com o PSOD e somos capazes de identificar a maioria das condições prévias que podem conduzir a este problema. Ao analisar proactivamente o seu ambiente, o Runecast Analyzer ajudá-lo-á a afastar-se destas questões, para que possa ter a paz de espírito que a maioria dos PSOD que se escondem no seu ambiente são evitados.
>> Descarregar o Runecast Analyzer para avaliação gratuita (na língua inglesa)
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Ebook – Como Lidar com PSOD (na língua inglesa)
Tudo o que precisa de saber sobre o PSOD (The Purple Screen of Death), num ebook do Runecast CTO Aylin Sali.