Jak radzić sobie z PSOD - Purpurowym ekranem śmierci

This article is available in the following languages:










Spis treści
Co to jest PSOD?
Dlaczego dochodzi do PSOD?
Jaki jest wpływ PSOD?
Co zrobić, gdy dojdzie do PSOD?
Jak temu zapobiec?
TL;DR
Najbardziej kłopotliwym aspektem PSOD jest utrata zaufania do infrastruktury i niepokój, jaki ona wywołuje. Dopóki nie rozwiążesz przyczyny źródłowej, myśl, że to może się powtórzyć lub zdarzyć na innym serwerze, może nie dawać Ci spać po nocach.
Użyj programu Runecast Analyzer (bezpłatna wersja testowa), aby sprawdzić, czy któryś z hostów jest dotknięty stanami, które mogą powodować fioletowy ekran śmierci VMware.
Co to jest PSOD?
PSOD to skrót od Purple Screen of Diagnostics, często określany jako Purple Screen of Death (pochodzi od bardziej znanego Blue Screen of Death spotykanego czasem w Microsoft Windows).
Jest to ekran diagnostyczny wyświetlany przez VMware ESXi, gdy jądro wykryje błąd krytyczny, z którego nie jest w stanie bezpiecznie wyjść lub nie może kontynuować pracy bez znacznie większego ryzyka utraty danych.
Pokazuje on stan pamięci w momencie wystąpienia awarii, a także dodatkowe szczegóły, które są ważne przy usuwaniu przyczyn awarii: wersja i kompilacja ESXi, typ wyjątku, zrzut rejestru, backtrace, czas pracy serwera, komunikaty o błędach i informacje o zrzucie rdzenia (plik wygenerowany po błędzie zawierający dalsze informacje diagnostyczne).
Ekran ten jest widoczny na konsoli serwera. Aby go zobaczyć, musisz być albo w centrum danych i podłączyć monitor, albo zdalnie, używając zarządzania out-of-band serwera (iLO, iDRAC, IMM... w zależności od dostawcy).
CZY WIESZ, ŻE?
Ekran jest określany jako fioletowy lub różowy, ale w rzeczywistości jest to kolor Dark Magenta (RGB:171,0,171 | CMYK:0.00, 1.00, 0.00, 0.33)
Dlaczego dochodzi do PSOD?
PSOD jest paniką jądra (Kernel panic). Mimo, że wszyscy wiemy, że ESXi nie jest oparty na UNIX-ie, implementacja paniki pasuje do definicji UNIX-a. Jądro ESXi (vmkernel) uruchamia ten środek bezpieczeństwa w odpowiedzi na zdarzenie/błąd, który jest nienaprawialny i oznaczałby, że kontynuowanie pracy stanowiłoby wysokie ryzyko dla usług i maszyn wirtualnych. Mówiąc prościej: kiedy host ESXi czuje, że został uszkodzony, popełnia "seppuku" i wykrwawiając się purpurową krwią, pisze list pożegnalny, w którym opisuje dlaczego to zrobił!
Najczęstszymi przyczynami PSOD są:
1. Awarie sprzętowe, najczęściej związane z pamięcią RAM lub procesorem. Zwykle wyrzucają one błąd "MCE" lub "NMI".
- "MCE" - Machine Check Exception, czyli mechanizm w procesorze służący do wykrywania i zgłaszania problemów sprzętowych. W kodach wyświetlanych na purpurowym ekranie znajdują się ważne szczegóły pozwalające na zidentyfikowanie pierwotnej przyczyny problemu.
- "NMI" - non-maskable interrupt, czyli przerwanie sprzętowe, które nie może być zignorowane przez procesor. Ponieważ NMI jest bardzo ważnym komunikatem o awarii sprzętowej, domyślną reakcją począwszy od ESXi 5.0 i nowszych jest wywołanie PSOD. Wcześniejsze wersje po prostu rejestrowały błąd i kontynuowały pracę. Podobnie jak w przypadku MCE, fioletowy ekran spowodowany przez NMI dostarcza ważne kody, które są kluczowe dla rozwiązywania problemów.
2. Błędy w oprogramowaniu
- nieprawidłowe interakcje między komponentami SW ESXi (np. KB2105711)
- warunki wyścigu (np. KB2136430)
- brak zasobów: pamięci, sterty, bufora (np. KB2034111, KB2150280)
- nieskończona pętla + przepełnienie stosu (ex: KB2105522)
- niewłaściwe lub nieobsługiwane parametry konfiguracyjne (np. KB2012125, KB2127997)
3. Błędnie działające sterowniki; błędy w sterownikach, które próbują uzyskać dostęp do nieprawidłowego indeksu lub nieistniejącej metody (np. KB2148123)
CZY WIESZ, ŻE?
Możesz nawet uruchomić ręcznie PSOD w celach testowych lub jeśli jesteś po prostu ciekawy. Zaloguj się do hosta ESXi poprzez DCUI lub SSH z kontem uprzywilejowanym i uruchom:
vsish -e set /reliability/crashMe/Panic
Oczywiście zalecany jest system testowy, najlepiej wirtualny, zagnieżdżony ESXi, abyś mógł łatwo obserwować konsolę. Upewnij się również, że skończyłeś czytać ten artykuł, aby zrozumieć implikacje tego działania i jego wpływ na Twój system testowy.
Jaki jest wpływ PSOD?
Kiedy dochodzi do Kernel paniki i host ulega awarii, kończą się wszystkie działające na nim usługi oraz wszystkie hostowane maszyny wirtualne. Maszyny wirtualne nie są zamykane, ale gwałtownie wyłączane. Jeśli host jest częścią klastra i masz skonfigurowany HA, te maszyny wirtualne zostaną uruchomione na innych hostach w klastrze. Oprócz przestoju i niedostępności maszyn wirtualnych w czasie, gdy są one wyłączone, niektóre krytyczne aplikacje, takie jak serwery baz danych, kolejki wiadomości lub zadania tworzenia kopii zapasowych mogą zostać dotknięte przez "brudne" wyłączenie.
Dodatkowo, wszystkie inne usługi świadczone przez hosta zostaną zakończone, więc jeśli Twój host jest członkiem klastra VSAN, PSOD wpłynie również na vSAN.
Dla mnie, najbardziej kłopotliwym aspektem PSOD jest to, że sprawia, że tracisz zaufanie do swojej infrastruktury i niepokój, który tworzy, przynajmniej dopóki nie dotrzesz do sedna sprawy. Ok, można wyzdrowieć przez ponowne uruchomienie i możesz mieć HA lub nawet FT, więc wpływ może nie być niszczycielski ... ale dopóki nie rozwiążesz głównej przyczyny, sama myśl, że może to się zdarzyć ponownie lub na innym serwerze, może spowodować bezsenność.
Co zrobić, gdy dojdzie do PSOD?
1. Przeanalizuj komunikat o purpurowym ekranie
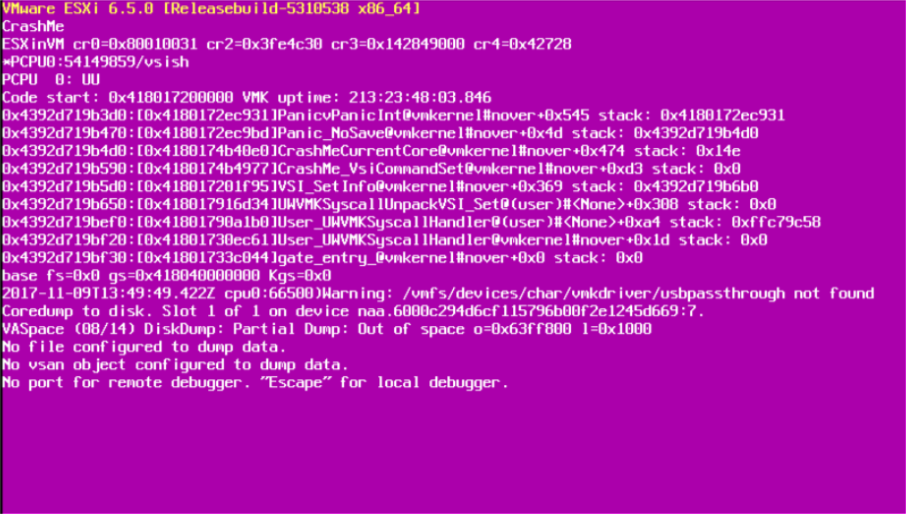
Jedną z najważniejszych rzeczy do zrobienia, gdy masz PSOD jest zrobienie zrzutu ekranu. Jeśli łączysz się zdalnie (IMM, iLO, iDRAC...) z konsolą, łatwo będzie zrobić zrzut ekranu, ale jeśli musisz iść do centrum danych, możesz dosłownie wyjąć telefon i pstryknąć zdjęcie ekranu. Na tym ekranie znajduje się wiele przydatnych informacji o przyczynie awarii.
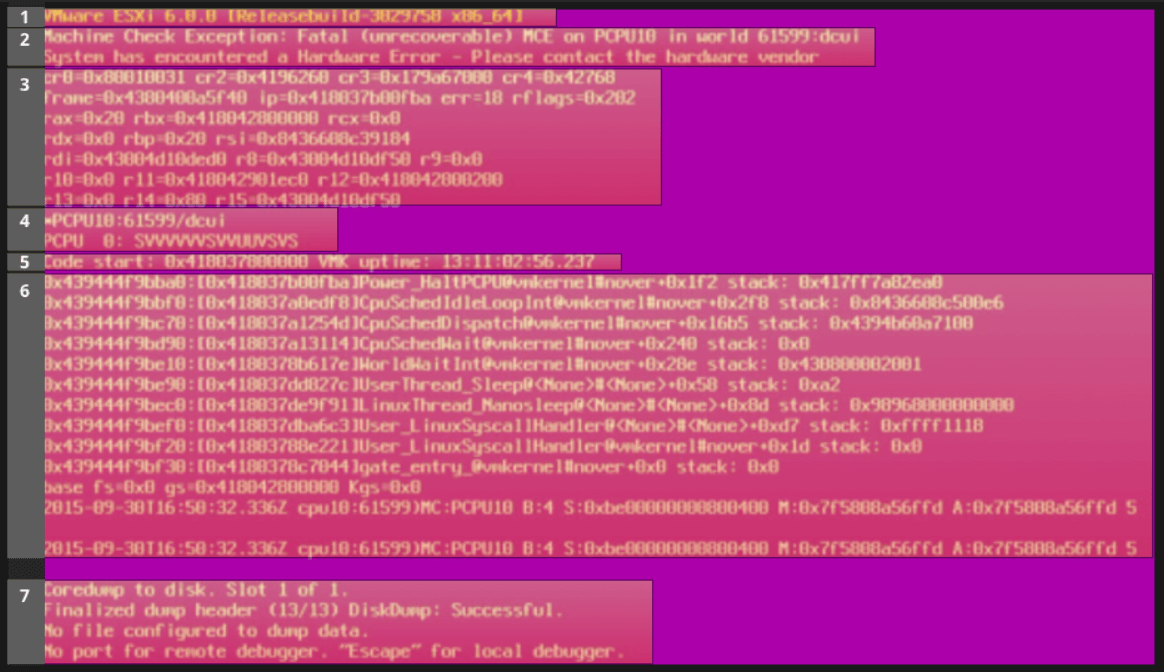
2. Skontaktuj się z pomocą techniczną VMware
Przed rozpoczęciem dalszego dochodzenia i rozwiązywania problemów warto skontaktować się z działem pomocy technicznej VMware, jeśli użytkownik ma podpisaną umowę na świadczenie pomocy technicznej. Równolegle z dochodzeniem będą oni w stanie pomóc w przeprowadzeniu analizy przyczyn źródłowych (RCA).
3. Ponowne uruchomienie dotkniętego hosta ESXi
Aby odzyskać serwer, należy go ponownie uruchomić. Radziłbym również pozostawienie go w trybie konserwacji do czasu wykonania pełnego RCA, zidentyfikowania przyczyny i jej naprawienia. Jeśli nie możesz pozwolić sobie na utrzymanie go w trybie konserwacji, przynajmniej dostrój reguły DRS tak, aby tylko nieistotne maszyny wirtualne były uruchamiane na nim, tak aby w przypadku kolejnego PSOD wpływ był minimalny.
4. Pobierz zrzut rdzenia
Po uruchomieniu serwera powinieneś zebrać coredump. Coredump, nazywany również vmkernel-zdump, jest plikiem zawierającym logi z podobnymi, ale bardziej szczegółowymi informacjami do tych widocznych na fioletowym ekranie diagnostycznym i będzie używany w dalszym rozwiązywaniu problemów. Nawet jeśli przyczyna awarii może wydawać się oczywista na podstawie komunikatu PSOD, który przeanalizowałeś w kroku 1, zaleca się potwierdzenie jej poprzez przejrzenie logów z coredump.
W zależności od Twojej konfiguracji możesz mieć zrzut rdzenia w jednej z tych postaci:
a. Na partycji scratch
b. Jako plik .dump na jednym z magazynów danych hosta
c. Jako plik .dump na vCenter - poprzez usługę netdump
Coredump staje się szczególnie ważny, jeśli konfiguracja hosta ma być automatycznie resetowana po PSOD, w takim przypadku nie zobaczysz komunikatu na ekranie.
Możesz skopiować plik dumpfile z hosta ESXi za pomocą SCP, a następnie otworzyć go za pomocą edytora tekstu (np. Notepad++). Plik ten będzie zawierał zawartość pamięci w momencie awarii, a pierwsze jego części zawierają komunikaty, które widziałeś na fioletowym ekranie. Cały plik może być zażądany przez obsługę VMware, ale możesz wyodrębnić tylko log vmkernel, który jest nieco bardziej ... przyswajalny:
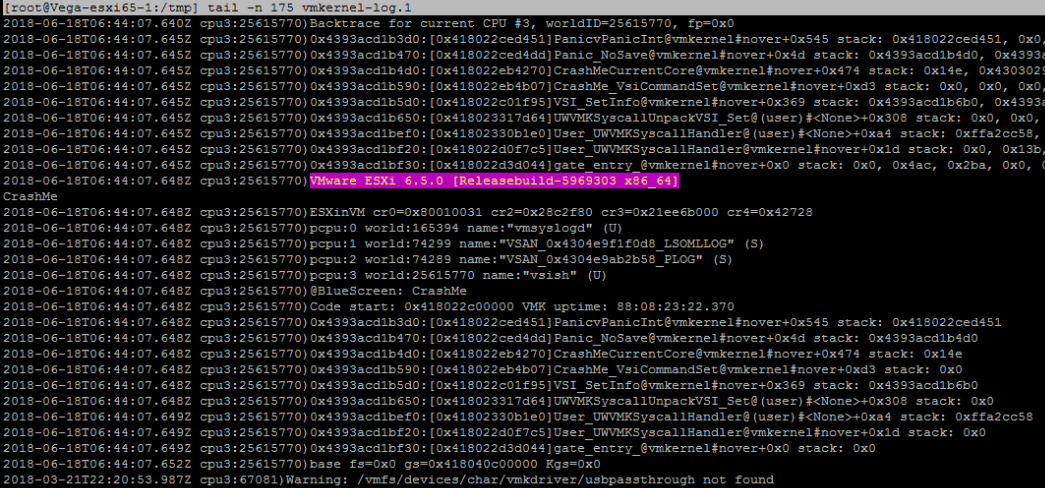
5. Rozszyfruj błąd
Rozwiązywanie problemów i analiza przyczyn źródłowych może sprawić, że poczujemy się jak Sherlock Holmes. PSOD może czasami zamienić się w historię inspirowaną Arthurem Conan Doyle'em, ale w większości przypadków jest to całkiem prosty proces, w którym trudno będzie dotrzeć do piątego "dlaczego" z techniki 5 Whys.
Najważniejszym symptomem i tym, od którego należy zacząć, jest komunikat o błędzie generowany przez fioletowy ekran. Na szczęście liczba komunikatów o błędach, które mogą zostać wygenerowane, jest skończona:
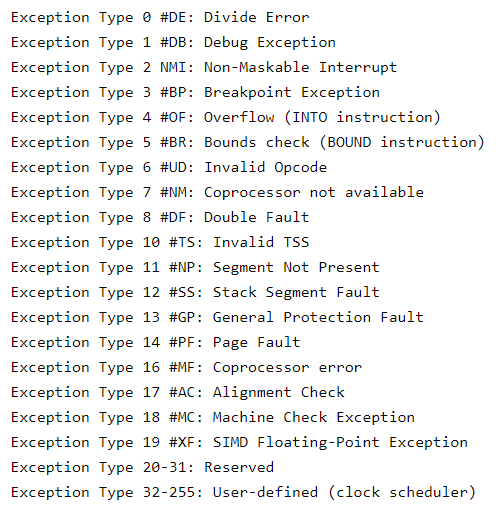
Ponieważ panika jądra jest obsługiwana przez procesor, więcej informacji na temat tych wyjątków można znaleźć w podręcznikach Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 1: Basic Architecture oraz Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 3A.
Najczęstsze przypadki są omówione w oddzielnych artykułach VMware KB, a ja tutaj zachowam tylko tabelę referencyjną takich błędów, ponieważ artykuły te są bardzo szczegółowe i dobrze udokumentowane. Użyj tej tabeli jako indeksu dla błędów PSOD:
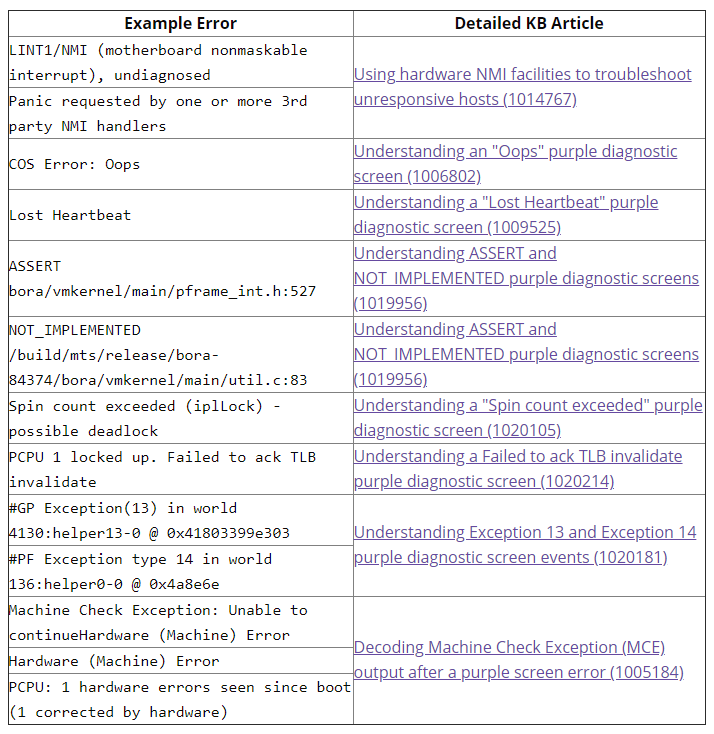
6. Sprawdź dzienniki
Może się zdarzyć, że przyczyna nie jest oczywista patrząc na komunikat purpurowego ekranu lub na logi zrzutu rdzenia, więc następnym miejscem, gdzie należy szukać wskazówek są logi hosta, szczególnie w przedziale czasowym tuż przed PSOD. Nawet jeśli czujesz, że zlokalizowałeś przyczynę, nadal wskazane jest, abyś nie był łatwowierny i potwierdził ją przeglądając logi.
Jeśli administrujesz środowiskiem korporacyjnym, prawdopodobnie masz pod ręką jakieś wyspecjalizowane rozwiązanie do zarządzania logami (jak VMware Log Insight lub SolarWinds LEM), więc przeglądanie tych logów będzie łatwe, ale jeśli nie masz takiego rozwiązania, możesz je łatwo wyeksportować.
Najciekawszymi plikami logów do zbadania byłyby:

Jak zapobiec PSOD?
Większość PSOD związanych z oprogramowaniem jest rozwiązywana przez poprawki, więc upewnij się, że jesteś na bieżąco z najnowszymi wersjami.
Upewnij się, że Twoje serwery znajdują się na liście kontrolnej VMware Hardware Compatibility Checklist, wraz ze wszystkimi urządzeniami i adapterami. Uchroni to przed niektórymi nieoczekiwanymi problemami związanymi ze sprzętem, ale także zapewni, że obsługę VMware będzie w stanie udzielić pomocy w przypadku PSOD.
Jak opisano powyżej w sekcji "Dlaczego tak się dzieje", nieprawidłowo działające sterowniki są również częstą przyczyną PSOD, dlatego konieczne jest regularne sprawdzanie stron wsparcia technicznego producentów pod kątem aktualizacji firmware i sterowników, a zwłaszcza udokumentowanych sterowników powodujących PSOD, aby jak najszybciej zareagować poprzez ich aktualizację.
W Runecast regularnie analizujemy całą Bazę wiedzy VMware (kb.vmware.com), która składa się z ponad 30 000 artykułów. Wydobywamy z niej użyteczne informacje, aby proaktywnie zwiększać odporność, bezpieczeństwo i wydajność zwirtualizowanych infrastruktur. Jesteśmy bardzo dobrze zaznajomieni z PSOD i potrafimy zidentyfikować większość warunków wstępnych, które mogą prowadzić do tego problemu. Poprzez proaktywną analizę środowiska, Runecast Analyzer pomoże Ci uniknąć tych problemów, dzięki czemu możesz mieć pewność, że większość PSOD czyhających na Twoje środowisko zostało zażegnanych.
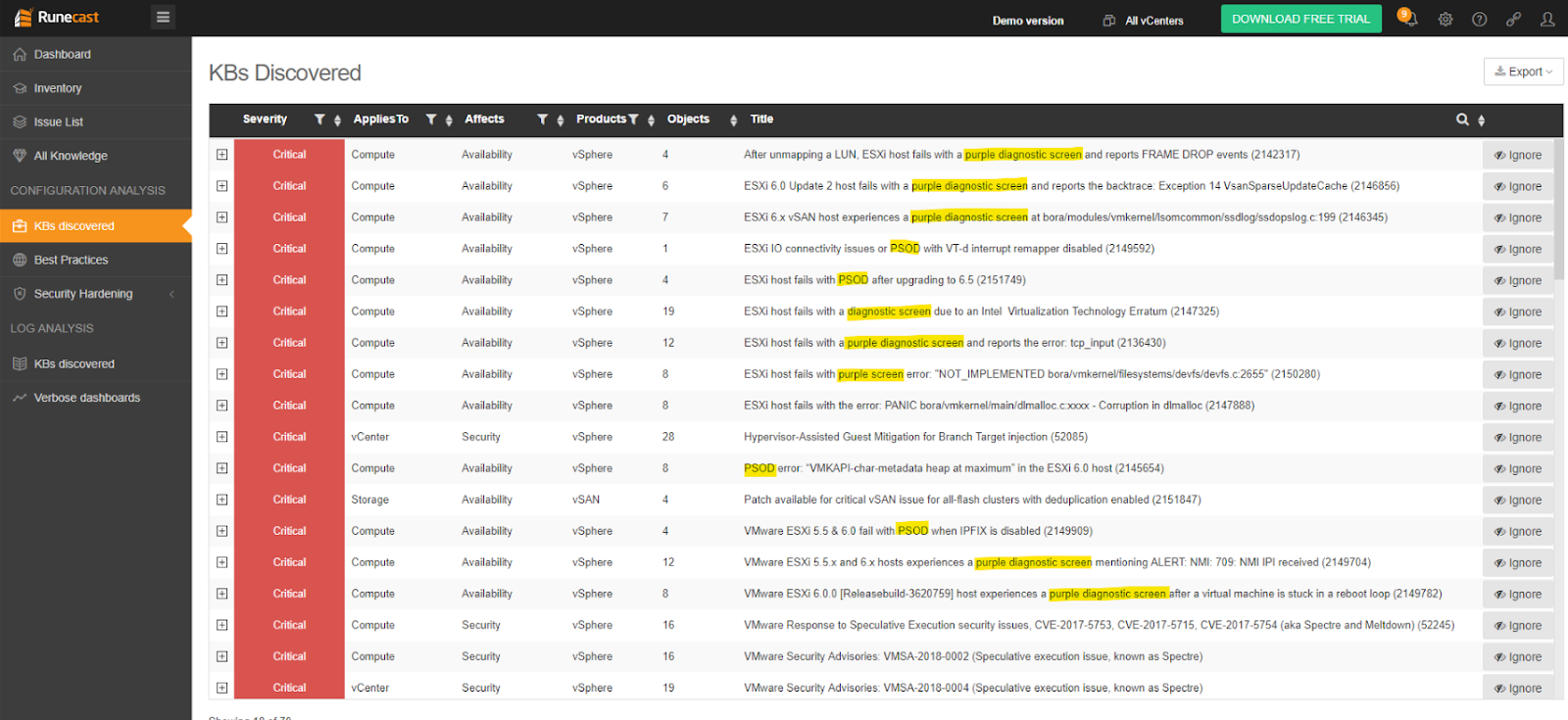
>> Pobierz bezpłatną wersję próbną Runecast Analyzer (w języku angielskim)
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Ebook - Jak radzić sobie z PSOD
Wszystko, co musisz wiedzieć o PSOD (The Purple Screen of Death), w jednym Ebooku autorstwa Runecast CTO Aylina Sali. Ebook jest w języku angielskim.