Comment faire face au PSOD – L'écran violet de la mort

This article is available in the following languages:










Contenu
Qu'est-ce que le PSOD ?
Pourquoi cela se produit-il ?
Quel est l'impact ?
Que faire lorsque cela se produit ?
Comment le prévenir ?
TL;DR
L'aspect le plus gênant d'un PSOD est qu'il vous fait perdre confiance dans votre infrastructure et l'anxiété qu'il crée. Tant que vous n'avez pas résolu la cause première, l'idée que cela puisse se reproduire ou se produire sur un autre serveur peut vous empêcher de dormir. Utilisez Runecast Analyzer (essai gratuit) pour vérifier si l'un de vos hôtes est affecté par des conditions pouvant entraîner la mort de l'écran violet VMware.
Qu'est-ce que le PSOD ?
PSOD signifie Purple Screen of Diagnostics, souvent appelé Purple Screen of Death (dérivé du plus connu Blue Screen of Death parfois rencontré sur Microsoft Windows).
Il s'agit d'un écran de diagnostic affiché par VMware ESXi lorsque le ‘kernel’ détecte une erreur fatale dont il est incapable de se remettre en marche en toute sécurité, ou dont il ne peut continuer à se servir sans courir un risque beaucoup plus élevé de perte de données importante.
Il indique l'état de la mémoire au moment de l'accident ainsi que des détails supplémentaires qui sont importants pour trouver la cause de l'accident : Version et construction de l'ESXi, type d'exception, vidage des registres, rétro-traçage, temps de fonctionnement du serveur, messages d'erreur et informations sur le “core dump” (un fichier généré après l'erreur, contenant des informations de diagnostic supplémentaires).
Cet écran est visible sur la console du serveur. Pour le voir, vous devez soit être dans le centre de données et connecter un moniteur, soit utiliser à distance la gestion hors bande du serveur (iLO, iDRAC, IMM... selon votre fournisseur).
LE SAVIEZ-VOUS ?
L'écran est désigné comme étant soit violet, soit rose, mais en fait la couleur est magenta foncé (RGB:171,0,171 | CMYK:0.00, 1.00, 0.00, 0.33)
Pourquoi le PSOD a-t-elle lieu ?
Le PSOD est une panique du noyau. Même si nous savons tous que l'ESXi n'est pas basé sur UNIX, l'implémentation de la panique correspond à la définition d'UNIX. Le noyau ESXi (vmkernel) déclenche cette mesure de sécurité en réponse à un événement/erreur qui est irrécupérable et qui signifierait que continuer à fonctionner présenterait un risque élevé pour les services et les VM. Pour faire simple : lorsque l'hôte de l'ESXi se sent corrompu, il commet un "seppuku" et, tout en saignant de son sang violet, écrit une lettre de suicide détaillant les raisons de son acte !
Les causes les plus courantes d'une PSOD sont les suivantes :
1. Défaillances matérielles, principalement liées à la mémoire vive ou à l'unité centrale. Elles provoquent généralement une erreur "MCE" ou "NMI".
- "MCE" - Machine Check Exception, qui est un mécanisme au sein du CPU pour détecter et signaler les problèmes de matériel. Les codes affichés sur l'écran violet contiennent des détails importants pour identifier la cause profonde du problème.
- "NMI" - interruption non masquable, c'est-à-dire une interruption matérielle qui ne peut être ignorée par le processeur. Étant donné que NMI est un message très important concernant une panne de HW, la réponse par défaut à partir de ESXi 5.0 est de déclencher un PSOD. Les versions antérieures ne faisaient qu'enregistrer l'erreur et continuer. Comme pour les MCE, l'écran violet causé par les INM fournira des codes importants qui sont cruciaux pour le dépannage.
2. Bugs logiciels
- les interactions incorrectes entre les composants de l'ESXi SW (ex : KB2105711)
- les conditions de course (ex : KB2136430)
- à court de ressources : mémoire, tas, tampon (ex : KB2034111, KB2150280)
- boucle infinie + débordement de pile (ex : KB2105522)
- des paramètres de configuration incorrects ou non pris en charge (ex : KB2012125, KB2127997)
3. Mauvais comportement des pilotes ; bogues dans les pilotes qui tentent d'accéder à un index incorrect ou à une méthode inexistante (ex : KB2148123)
LE SAVIEZ-VOUS ?
Vous pouvez même déclencher manuellement une PSOD à des fins de test ou si vous êtes simplement curieux de voir ce qui se passe.
Connectez-vous à l'hôte ESXi via DCUI ou SSH avec un compte privilégié et exécutez :
vsish -e set /reliability/crashMe/Panic
Il est évident qu'un système de test est recommandé, idéalement un ESXi virtuel imbriqué afin que vous puissiez facilement observer la console. Assurez-vous également de bien terminer la lecture de cet article pour comprendre les implications de cette action et l'effet sur votre système de test.
Quel est l'impact de le PSOD ?
Lorsque la panique se produit et que l'hôte se plante, il met fin à tous les services qui y sont exécutés ainsi qu'à toutes les machines virtuelles hébergées. Les machines virtuelles ne sont pas éteintes gracieusement, mais plutôt brusquement. Si l'hôte fait partie d'un cluster et que vous avez configuré HA, ces VM seront démarrées sur les autres hôtes du cluster. Outre l'arrêt et l'indisponibilité des machines virtuelles pendant la période d'arrêt, certaines applications critiques comme les serveurs de base de données, les files d'attente de messages ou les tâches de sauvegarde peuvent être affectées par l'arrêt "sale".
En outre, tous les autres services fournis par l'hôte seront interrompus. Ainsi, si votre hôte est membre d'un cluster VSAN, un PSOD aura également un impact sur le vSAN.
Pour moi, l'aspect le plus gênant d'un PSOD est qu'il vous fait perdre confiance dans votre infrastructure et l'anxiété qu'il crée, du moins jusqu'à ce que vous en connaissiez le fond. Ok, vous pouvez vous en remettre en redémarrant et vous pouvez avoir HA ou même FT, donc l'impact peut ne pas être dévastateur... mais jusqu'à ce que vous ne résolvez pas la cause première, l'idée que cela puisse se reproduire ou se produire sur un autre serveur peut vous empêcher de dormir la nuit.
Que faire en cas de PSOD ?
1. Analyser le message de l'écran violet
L'une des choses les plus importantes à faire lorsque vous avez un PSOD est de prendre une capture d'écran. Si vous vous connectez à distance (IMM, iLO, iDRAC...) à la console, il sera facile de faire une capture d'écran, mais si vous devez vous rendre au datacenter, vous devrez peut-être littéralement sortir votre téléphone et prendre une photo de l'écran. Cet écran contient beaucoup d'informations utiles sur la cause du crash.

2. Contactez le support VMware
Avant d'entamer une enquête plus approfondie et de procéder à un dépannage, il est conseillé de contacter le support VMware, si vous avez un contrat de support. Parallèlement à votre enquête, ils pourront vous aider à effectuer l'analyse des causes profondes (RCA).
3. Redémarrer l'hôte ESXi affecté
Pour récupérer le serveur, vous devez le redémarrer. Je vous conseille également de le maintenir en mode de maintenance jusqu'à ce que vous ayez effectué la RCA complète, que vous en ayez identifié la cause et que vous l'ayez réparée. Si vous ne pouvez pas vous permettre de le garder en mode maintenance, au moins affinez vos règles DRS pour que seules les VM sans importance fonctionnent dessus, de sorte que si un autre PSOD frappe, l'impact sera minime.
4. Obtenir la décharge de carottes
Après le démarrage du serveur, vous devez récupérer le coredump. Le coredump, également appelé vmkernel-zdump, est un fichier contenant des logs avec des informations similaires, mais plus détaillées, à celles qui sont affichées sur l'écran de diagnostic violet et qui seront utilisées pour le dépannage ultérieur. Même si la cause de l'accident peut sembler évidente à partir du message PSOD que vous avez analysé à l'étape 1, il est conseillé de la confirmer en examinant les journaux du coredump.
En fonction de votre configuration, vous pouvez avoir le dépôt central sous l'une de ces formes :
a. Sur la partition à gratter
b. En tant que fichier .dump sur l'un des magasins de données de l'hôte
c. En tant que fichier .dump sur le vCenter - via le service netdump
Le coredump devient particulièrement important si la configuration de l'hôte doit se réinitialiser automatiquement après un PSOD, auquel cas vous ne verrez pas le message à l'écran.
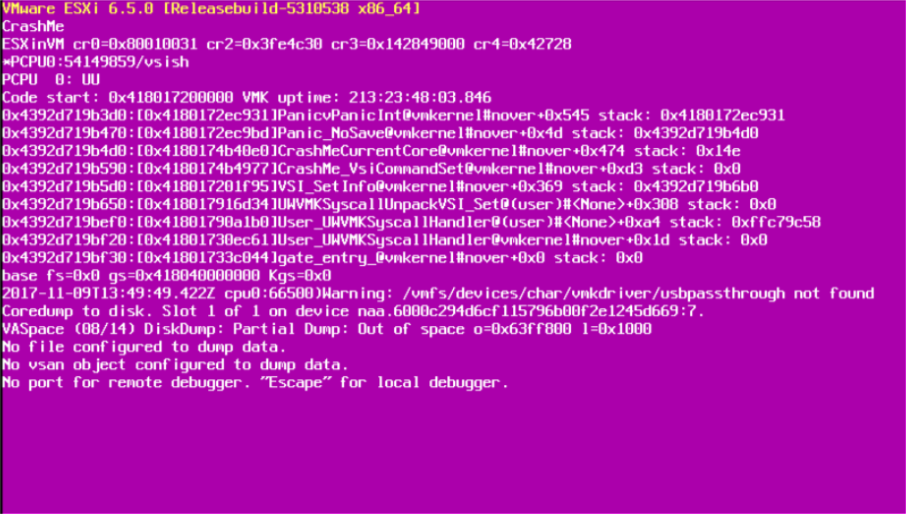
Vous pouvez copier le fichier de vidage hors de l'hôte ESXi en utilisant SCP et l'ouvrir ensuite à l'aide d'un éditeur de texte (comme Notepad++). Celui-ci contiendra le contenu de la mémoire au moment du plantage et les premières parties de celle-ci contiendront les messages que vous avez vus sur l'écran violet. L'ensemble du fichier peut être demandé par le support VMware, mais vous ne pouvez extraire que le journal vmkernel, qui est un peu plus ... digeste :
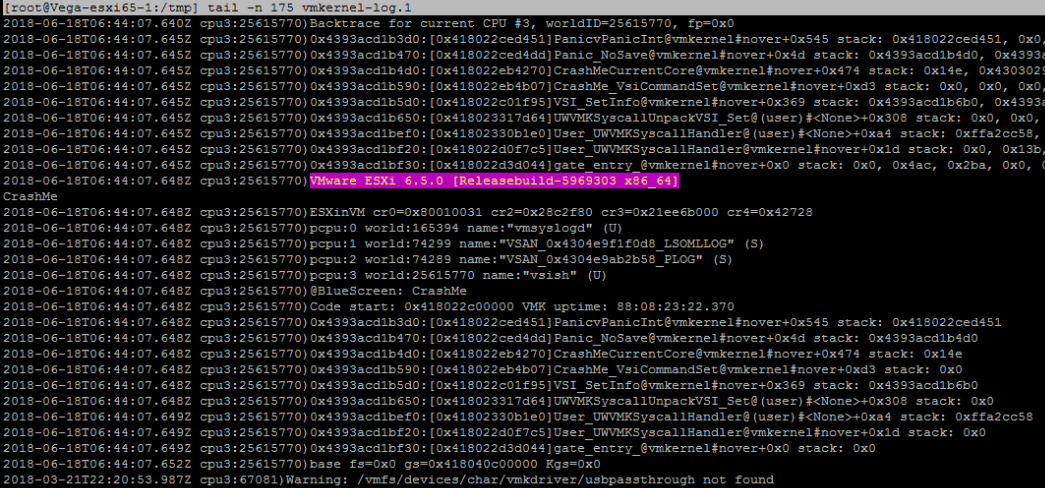
5. Déchiffrer l'erreur
Le dépannage et l'analyse des causes profondes peuvent donner l'impression d'être Sherlock Holmes. Les PSOD peuvent parfois se transformer en une histoire inspirée d'Arthur Conan Doyle, mais dans la plupart des cas, c'est un processus assez simple où il sera difficile d'arriver au cinquième "pourquoi" de la technique des 5 pourquoi.
Le symptôme le plus important, et celui avec lequel vous devriez commencer, est le message d'erreur généré par l'écran violet. Heureusement, le nombre de messages d'erreur qui peuvent être produits est limité :
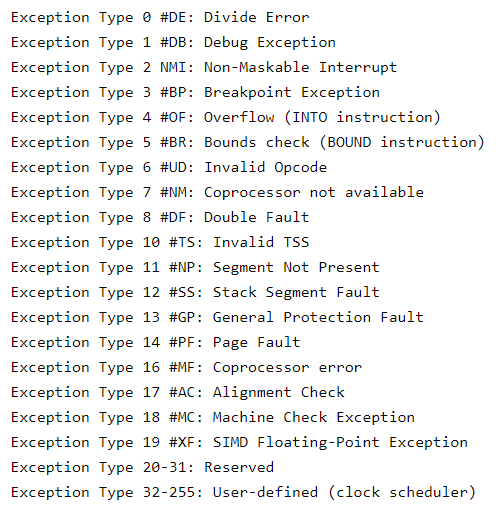
Comme la panique ‘kernel’ est gérée par l'unité centrale, pour plus d'informations sur ces exceptions, voir Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 1 : Basic Architecture et Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 3A.
Les cas les plus courants sont traités dans des articles séparés de VMware KB et je me contenterai de maintenir ici un tableau de référence de ces erreurs, car les articles sont très détaillés et bien documentés. Utilisez donc ce tableau comme un index des erreurs PSOD :
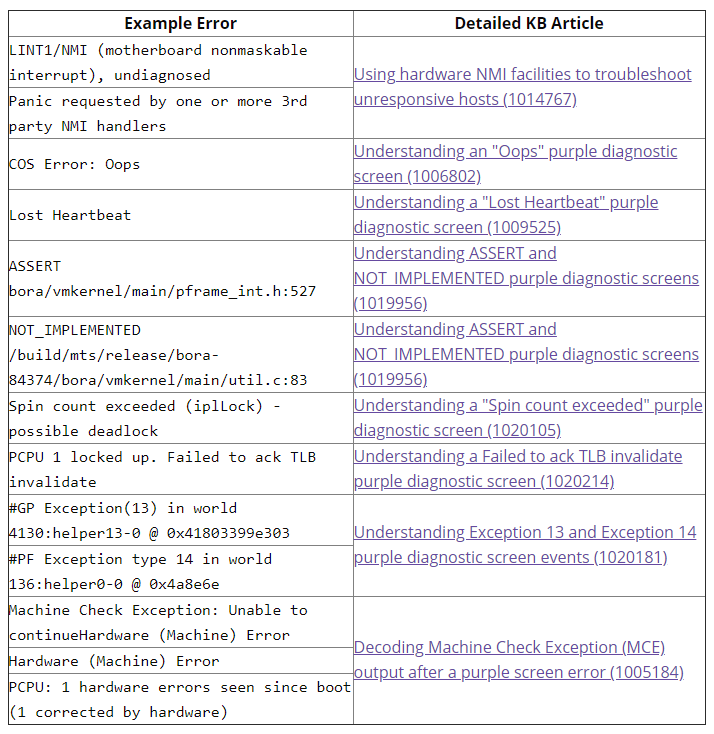
6. Vérifier les journaux
Il peut arriver que la cause ne soit pas très évidente en regardant le message de l'écran violet ou le log du “core dump”, donc le prochain endroit où chercher des indices est dans les journaux de l'hôte, surtout à l'intervalle de temps qui précède juste le PSOD. Même si vous pensez avoir trouvé la cause, il est conseillé d'éviter d'être parcimonieux et de la confirmer en consultant les logs.
Si vous administrez un environnement d'entreprise, il est probable que vous disposiez d'une solution de gestion des journaux spécialisée (comme VMware Log Insight ou SolarWinds LEM). Il sera donc facile de parcourir ces journaux, mais si vous ne disposez pas d'une gestion des journaux, vous pouvez facilement les exporter.
Les fichiers journaux les plus intéressants à explorer seraient :

Comment prévenir les PSOD ?
La plupart des PSOD liés aux logiciels sont résolus par des correctifs, alors assurez-vous d'être à jour avec les dernières versions.
Assurez-vous que vos serveurs figurent sur la liste de contrôle de compatibilité matérielle de VMware, ainsi que tous les périphériques et adaptateurs. Cela vous protégera de certains problèmes inattendus liés au matériel, mais garantira également que le support de VMware sera en mesure de vous aider en cas de PSOD.
Il est donc impératif de vérifier régulièrement sur les sites web d'assistance des fournisseurs les mises à jour des firmwares et des pilotes, et surtout les PSOD documentées, afin que les pilotes réagissent le plus rapidement possible en les mettant à niveau.
Chez Runecast, nous analysons régulièrement l'ensemble de la base de données VMware (kb.vmware.com) qui comprend plus de 30 000 articles. Nous en extrayons des informations exploitables afin de rendre les infrastructures virtualisées plus résilientes, plus sûres et plus efficaces. Nous connaissons très bien le PSOD et sommes en mesure d'identifier la plupart des conditions préalables qui peuvent conduire à ce problème. En analysant de manière proactive votre environnement, Runecast Analyzer vous aidera à vous éloigner de ces problèmes, afin que vous puissiez avoir la tranquillité d'esprit que la plupart des PSOD qui se cachent dans votre environnement sont évités.
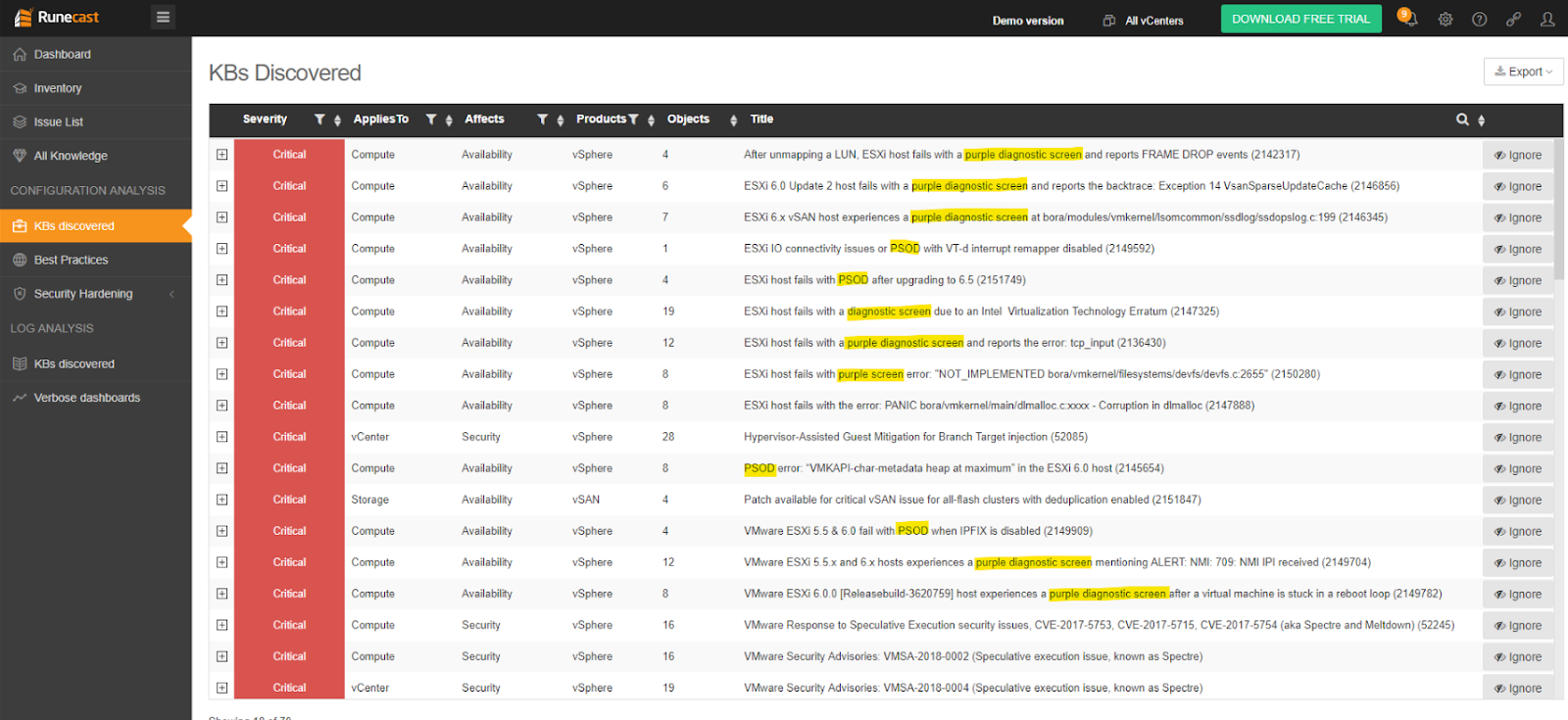
>> Télécharger l'essai gratuit de Runecast Analyzer (en anglais)
Click to view larger image ↑

Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Meet other Runecasters here:
Ebook – Comment traiter les PSOD (en anglais)
Tout ce que vous devez savoir sur le PSOD (The Purple Screen of Death), dans un ebook de la directrice technique de Runecast, Aylin Sali.